|
Joomla CMS
2.5.24 (avec JPlatform 11.4 inclus)
Documentation des API du CMS Joomla en version 2.5 et du framework Joomla Platform intégré
|
|
Joomla CMS
2.5.24 (avec JPlatform 11.4 inclus)
Documentation des API du CMS Joomla en version 2.5 et du framework Joomla Platform intégré
|
Fonctions membres publiques statiques | |
| static | splitCamelCase ($string) |
| static | increment ($string, $style= 'default', $n=0) |
| static | strpos ($str, $search, $offset=false) |
| static | strrpos ($str, $search, $offset=0) |
| static | substr ($str, $offset, $length=false) |
| static | strtolower ($str) |
| static | strtoupper ($str) |
| static | strlen ($str) |
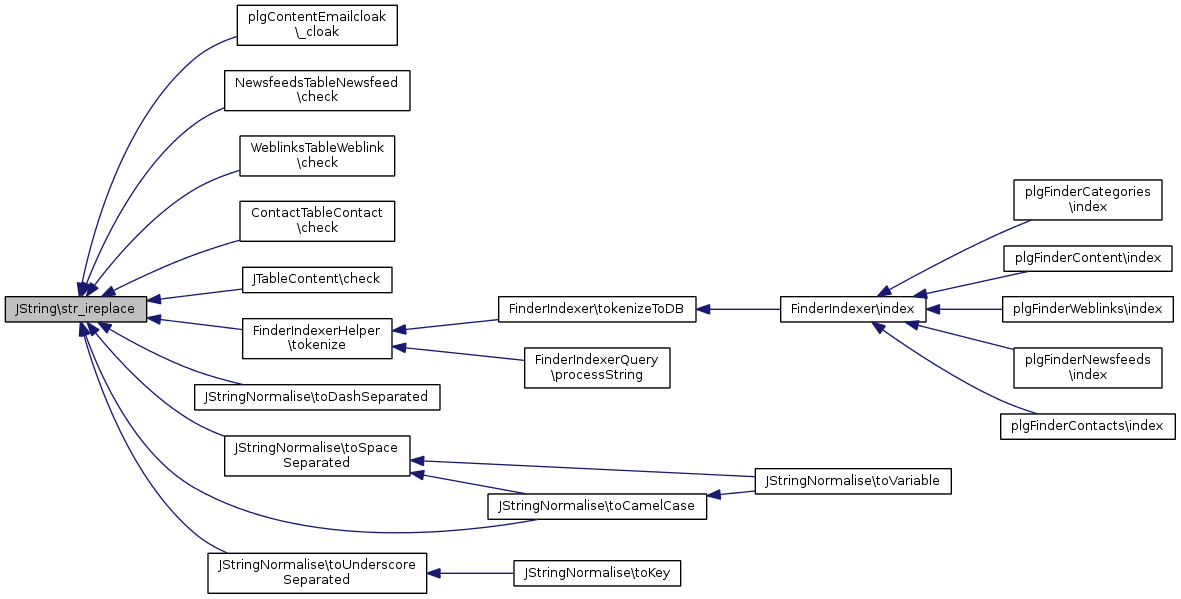
| static | str_ireplace ($search, $replace, $str, $count=null) |
| static | str_split ($str, $split_len=1) |
| static | strcasecmp ($str1, $str2, $locale=false) |
| static | strcmp ($str1, $str2, $locale=false) |
| static | strcspn ($str, $mask, $start=null, $length=null) |
| static | stristr ($str, $search) |
| static | strrev ($str) |
| static | strspn ($str, $mask, $start=null, $length=null) |
| static | substr_replace ($str, $repl, $start, $length=null) |
| static | ltrim ($str, $charlist=false) |
| static | rtrim ($str, $charlist=false) |
| static | trim ($str, $charlist=false) |
| static | ucfirst ($str, $delimiter=null, $newDelimiter=null) |
| static | ucwords ($str) |
| static | transcode ($source, $from_encoding, $to_encoding) |
| static | valid ($str) |
| static | compliant ($str) |
| static | parse_url ($url) |
Attributs protégés statiques | |
| static | $incrementStyles |
Fonctions membres privées statiques | |
| static | _iconvErrorHandler ($number, $message) |
|
staticprivate |
Catch an error and throw an exception.
| integer | $number | Error level |
| string | $message | Error message |
Références $message.
|
static |
Tests whether a string complies as UTF-8. This will be much faster than utf8_is_valid but will pass five and six octet UTF-8 sequences, which are not supported by Unicode and so cannot be displayed correctly in a browser. In other words it is not as strict as utf8_is_valid but it's faster. If you use it to validate user input, you place yourself at the risk that attackers will be able to inject 5 and 6 byte sequences (which may or may not be a significant risk, depending on what you are are doing)
| string | $str | UTF-8 string to check |
Références strlen().
 Voici le graphe d'appel pour cette fonction :
Voici le graphe d'appel pour cette fonction :
|
static |
Increments a trailing number in a string.
Used to easily create distinct labels when copying objects. The method has the following styles:
default: "Label" becomes "Label (2)" dash: "Label" becomes "Label-2"
| string | $string | The source string. |
| string | $style | The the style (default|dash). |
| integer | $n | If supplied, this number is used for the copy, otherwise it is the 'next' number. |
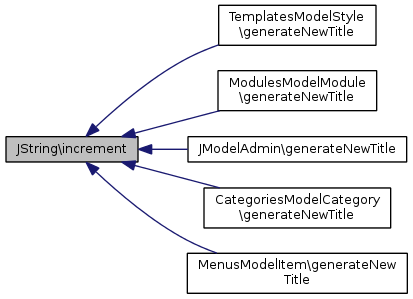
Référencé par TemplatesModelStyle\generateNewTitle(), ModulesModelModule\generateNewTitle(), JModelAdmin\generateNewTitle(), CategoriesModelCategory\generateNewTitle(), et MenusModelItem\generateNewTitle().
Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware replacement for ltrim()
Strip whitespace (or other characters) from the beginning of a string You only need to use this if you are supplying the charlist optional arg and it contains UTF-8 characters. Otherwise ltrim will work normally on a UTF-8 string
| string | $str | The string to be trimmed |
| string | $charlist | The optional charlist of additional characters to trim |
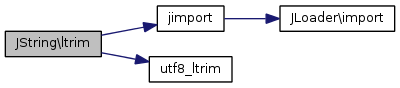
Références jimport(), et utf8_ltrim().
Voici le graphe d'appel pour cette fonction :
|
static |
Does a UTF-8 safe version of PHP parse_url function
| string | $url | URL to parse |
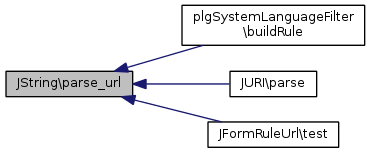
Référencé par plgSystemLanguageFilter\buildRule(), JURI\parse(), et JFormRuleUrl\test().
Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware replacement for rtrim() Strip whitespace (or other characters) from the end of a string You only need to use this if you are supplying the charlist optional arg and it contains UTF-8 characters. Otherwise rtrim will work normally on a UTF-8 string
| string | $str | The string to be trimmed |
| string | $charlist | The optional charlist of additional characters to trim |
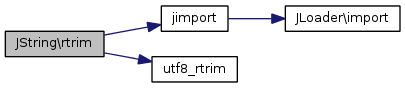
Références jimport(), et utf8_rtrim().
Voici le graphe d'appel pour cette fonction :
|
static |
Split a string in camel case format
"FooBarABCDef" becomes array("Foo", "Bar", "ABC", "Def"); "JFooBar" becomes array("J", "Foo", "Bar"); "J001FooBar002" becomes array("J001", "Foo", "Bar002"); "abcDef" becomes array("abc", "Def"); "abc_defGhi_Jkl" becomes array("abc_def", "Ghi_Jkl"); "ThisIsA_NASAAstronaut" becomes array("This", "Is", "A_NASA", "Astronaut")), "JohnFitzgerald_Kennedy" becomes array("John", "Fitzgerald_Kennedy")),
| string | $string | The source string. |
Référencé par JFormField\__construct().
Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware alternative to str_ireplace Case-insensitive version of str_replace
| string | $search | String to search |
| string | $replace | Existing string to replace |
| string | $str | New string to replace with |
| integer | $count | Optional count value to be passed by referene |
Références $count, jimport(), et utf8_ireplace().
Référencé par plgContentEmailcloak\_cloak(), NewsfeedsTableNewsfeed\check(), WeblinksTableWeblink\check(), ContactTableContact\check(), JTableContent\check(), JStringNormalise\toCamelCase(), JStringNormalise\toDashSeparated(), FinderIndexerHelper\tokenize(), JStringNormalise\toSpaceSeparated(), et JStringNormalise\toUnderscoreSeparated().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware alternative to str_split Convert a string to an array
| string | $str | UTF-8 encoded string to process |
| integer | $split_len | Number to characters to split string by |
Références jimport(), et utf8_str_split().
Voici le graphe d'appel pour cette fonction :
|
static |
UTF-8/LOCALE aware alternative to strcasecmp A case insensitive string comparison
| string | $str1 | string 1 to compare |
| string | $str2 | string 2 to compare |
| mixed | $locale | The locale used by strcoll or false to use classical comparison |
Références elseif, stristr(), utf8_strcasecmp(), et utf8_strtolower().
Référencé par JArrayHelper\_sortObjects().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
UTF-8/LOCALE aware alternative to strcmp A case sensitive string comparison
| string | $str1 | string 1 to compare |
| string | $str2 | string 2 to compare |
| mixed | $locale | The locale used by strcoll or false to use classical comparison |
Références elseif, et stristr().
Référencé par JArrayHelper\_sortObjects().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :UTF-8 aware alternative to strcspn Find length of initial segment not matching mask
| string | $str | The string to process |
| string | $mask | The mask |
| integer | $start | Optional starting character position (in characters) |
| integer | $length | Optional length |
Références elseif, jimport(), et utf8_strcspn().
Voici le graphe d'appel pour cette fonction :
|
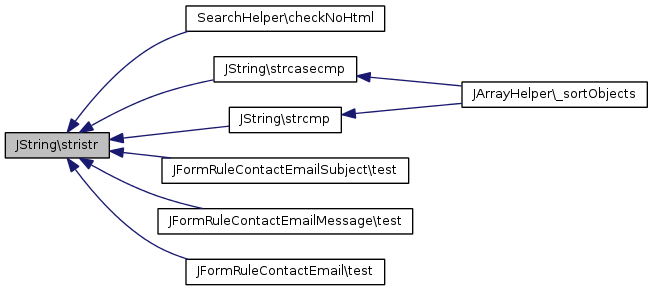
static |
UTF-8 aware alternative to stristr Returns all of haystack from the first occurrence of needle to the end. needle and haystack are examined in a case-insensitive manner Find first occurrence of a string using case insensitive comparison
| string | $str | The haystack |
| string | $search | The needle |
Références jimport(), et utf8_stristr().
Référencé par SearchHelper\checkNoHtml(), strcasecmp(), strcmp(), JFormRuleContactEmailSubject\test(), JFormRuleContactEmailMessage\test(), et JFormRuleContactEmail\test().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
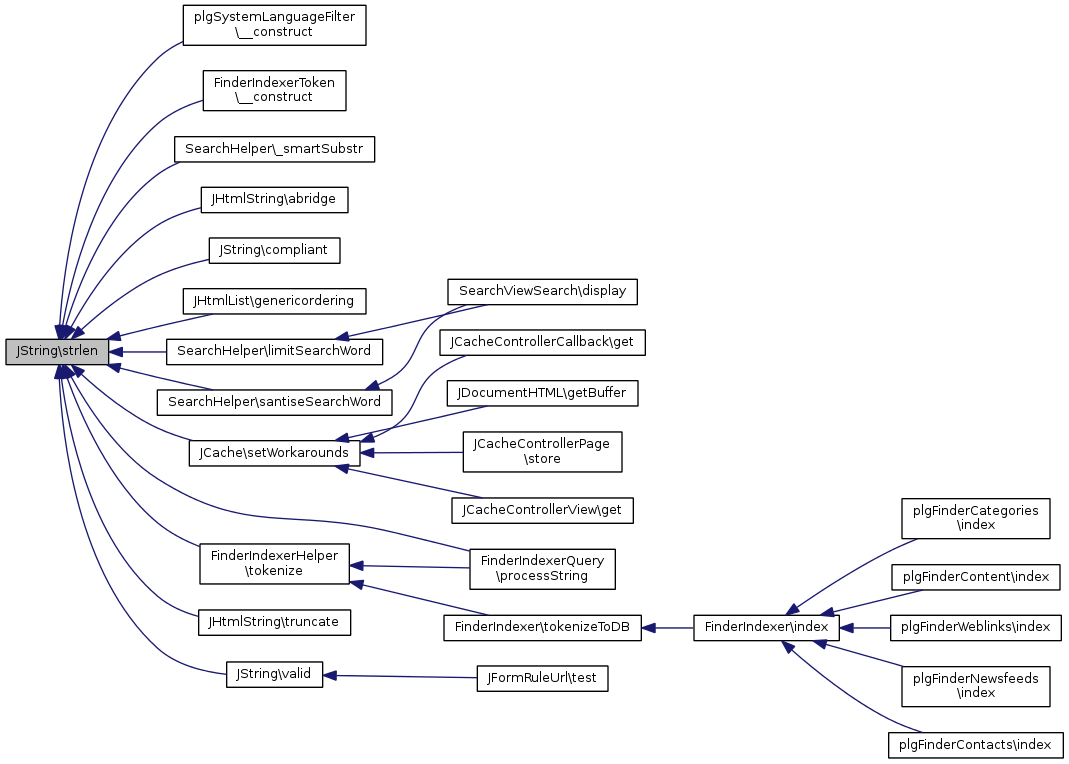
static |
UTF-8 aware alternative to strlen.
Returns the number of characters in the string (NOT THE NUMBER OF BYTES),
| string | $str | UTF-8 string. |
Références utf8_strlen().
Référencé par plgSystemLanguageFilter\__construct(), FinderIndexerToken\__construct(), SearchHelper\_smartSubstr(), JHtmlString\abridge(), compliant(), JHtmlList\genericordering(), SearchHelper\limitSearchWord(), FinderIndexerQuery\processString(), SearchHelper\santiseSearchWord(), JCache\setWorkarounds(), FinderIndexerHelper\tokenize(), JHtmlString\truncate(), et valid().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
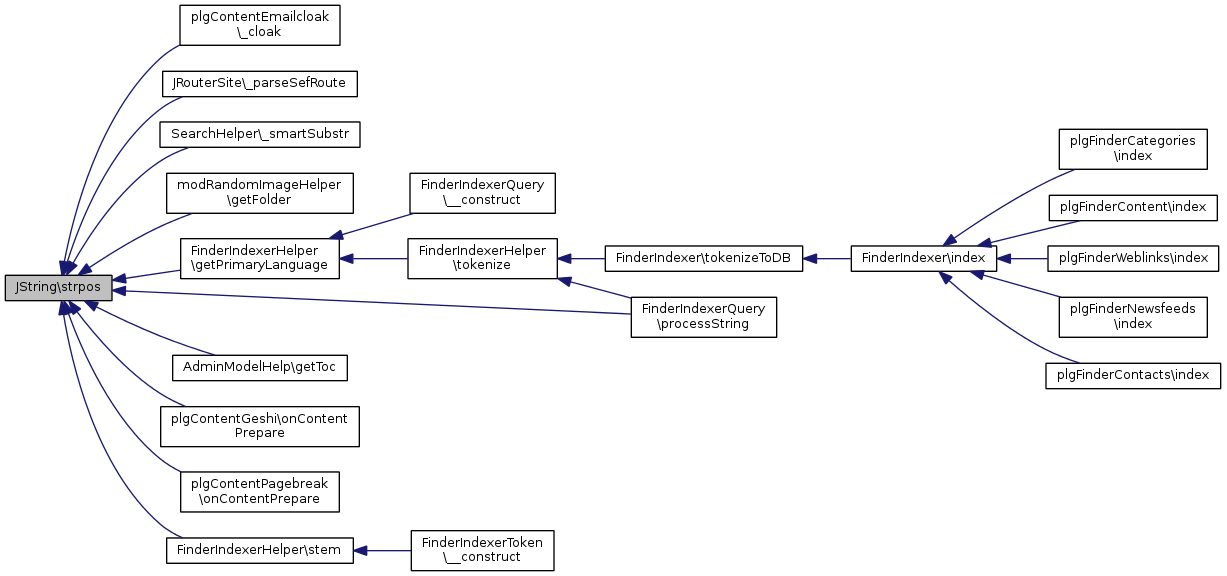
static |
UTF-8 aware alternative to strpos.
Find position of first occurrence of a string.
| string | $str | String being examined |
| string | $search | String being searched for |
| integer | $offset | Optional, specifies the position from which the search should be performed |
Références utf8_strpos().
Référencé par plgContentEmailcloak\_cloak(), JRouterSite\_parseSefRoute(), SearchHelper\_smartSubstr(), modRandomImageHelper\getFolder(), FinderIndexerHelper\getPrimaryLanguage(), AdminModelHelp\getToc(), plgContentGeshi\onContentPrepare(), plgContentPagebreak\onContentPrepare(), FinderIndexerQuery\processString(), et FinderIndexerHelper\stem().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
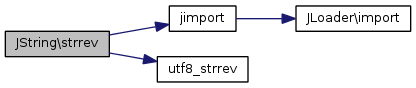
static |
UTF-8 aware alternative to strrev Reverse a string
| string | $str | String to be reversed |
Références jimport(), et utf8_strrev().
Voici le graphe d'appel pour cette fonction :
|
static |
UTF-8 aware alternative to strrpos Finds position of last occurrence of a string
| string | $str | String being examined. |
| string | $search | String being searched for. |
| integer | $offset | Offset from the left of the string. |
Références utf8_strrpos().
Référencé par JHtmlString\truncate().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :UTF-8 aware alternative to strspn Find length of initial segment matching mask
| string | $str | The haystack |
| string | $mask | The mask |
| integer | $start | Start optional |
| integer | $length | Length optional |
Références elseif, jimport(), null, et utf8_strspn().
Voici le graphe d'appel pour cette fonction :
|
static |
UTF-8 aware alternative to strtlower
Make a string lowercase Note: The concept of a characters "case" only exists is some alphabets such as Latin, Greek, Cyrillic, Armenian and archaic Georgian - it does not exist in the Chinese alphabet, for example. See Unicode Standard Annex #21: Case Mappings
| string | $str | String being processed |
Références utf8_strtolower().
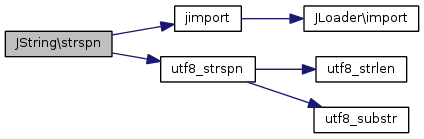
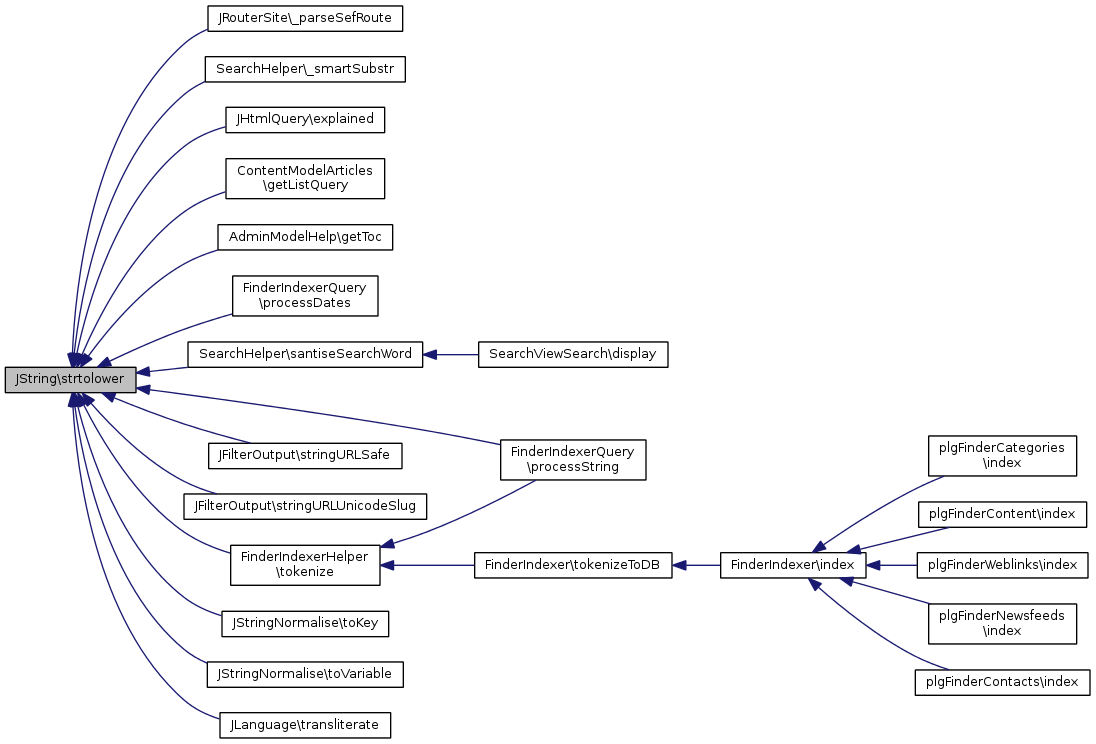
Référencé par JRouterSite\_parseSefRoute(), SearchHelper\_smartSubstr(), JHtmlQuery\explained(), ContentModelArticles\getListQuery(), AdminModelHelp\getToc(), FinderIndexerQuery\processDates(), FinderIndexerQuery\processString(), SearchHelper\santiseSearchWord(), JFilterOutput\stringURLSafe(), JFilterOutput\stringURLUnicodeSlug(), FinderIndexerHelper\tokenize(), JStringNormalise\toKey(), JStringNormalise\toVariable(), et JLanguage\transliterate().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware alternative to strtoupper Make a string uppercase Note: The concept of a characters "case" only exists is some alphabets such as Latin, Greek, Cyrillic, Armenian and archaic Georgian - it does not exist in the Chinese alphabet, for example. See Unicode Standard Annex #21: Case Mappings
| string | $str | String being processed |
Références utf8_strtoupper().
Voici le graphe d'appel pour cette fonction :
|
static |
UTF-8 aware alternative to substr Return part of a string given character offset (and optionally length)
| string | $str | String being processed |
| integer | $offset | Number of UTF-8 characters offset (from left) |
| integer | $length | Optional length in UTF-8 characters from offset |
Références utf8_substr().
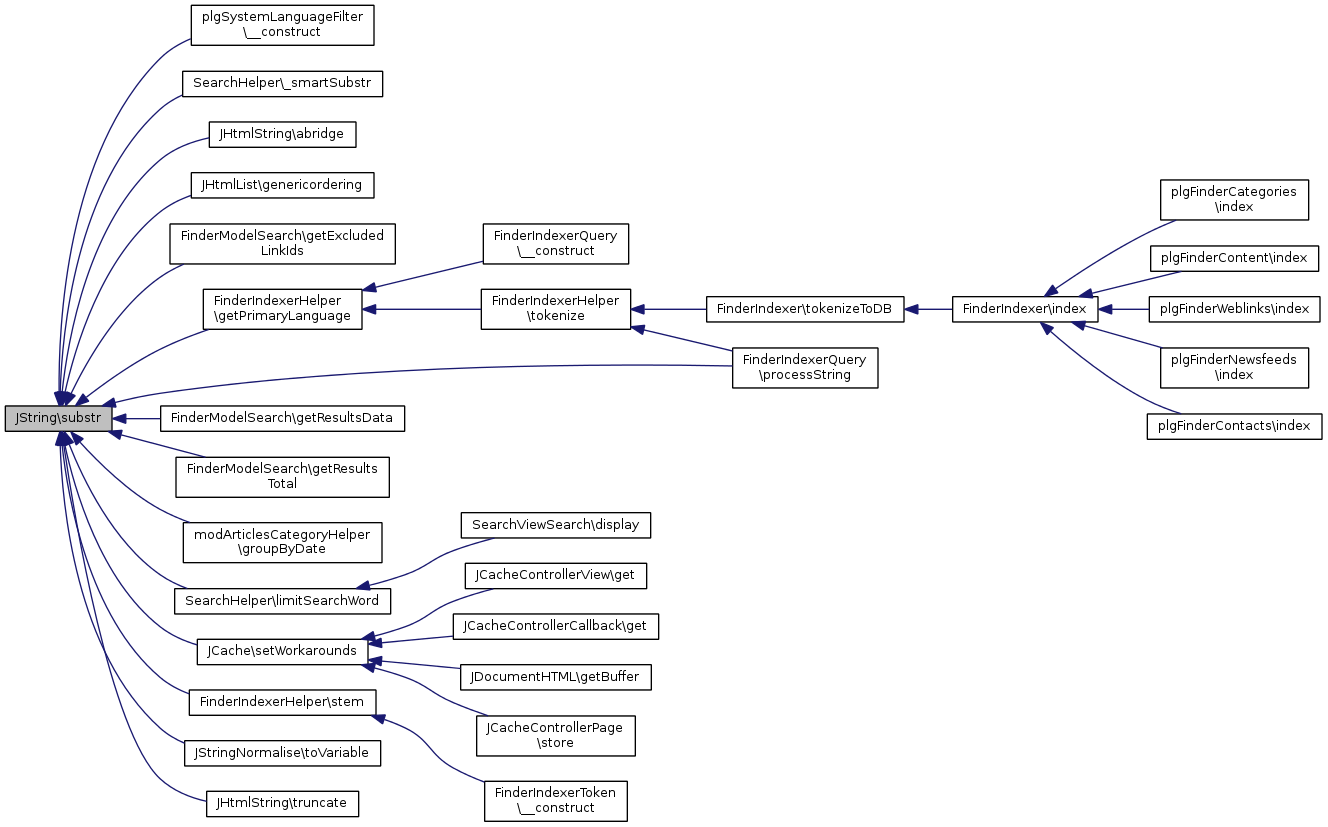
Référencé par plgSystemLanguageFilter\__construct(), SearchHelper\_smartSubstr(), JHtmlString\abridge(), JHtmlList\genericordering(), FinderModelSearch\getExcludedLinkIds(), FinderIndexerHelper\getPrimaryLanguage(), FinderModelSearch\getResultsData(), FinderModelSearch\getResultsTotal(), modArticlesCategoryHelper\groupByDate(), SearchHelper\limitSearchWord(), FinderIndexerQuery\processString(), JCache\setWorkarounds(), FinderIndexerHelper\stem(), JStringNormalise\toVariable(), et JHtmlString\truncate().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware substr_replace Replace text within a portion of a string
| string | $str | The haystack |
| string | $repl | The replacement string |
| integer | $start | Start |
| integer | $length | Length (optional) |
Références utf8_substr_replace().
Référencé par JStringNormalise\toVariable().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
|
static |
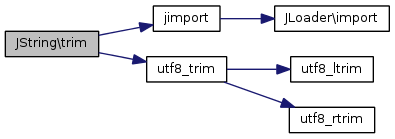
UTF-8 aware replacement for trim() Strip whitespace (or other characters) from the beginning and end of a string Note: you only need to use this if you are supplying the charlist optional arg and it contains UTF-8 characters. Otherwise trim will work normally on a UTF-8 string
| string | $str | The string to be trimmed |
| string | $charlist | The optional charlist of additional characters to trim |
Références jimport(), et utf8_trim().
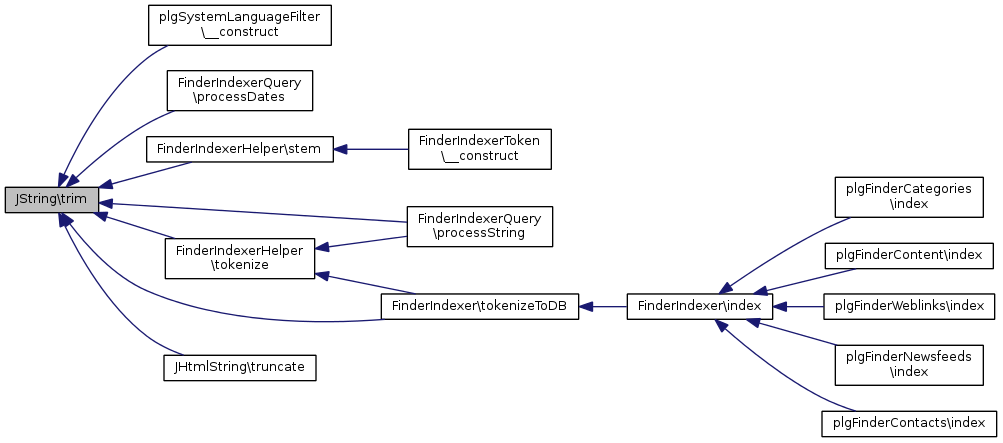
Référencé par plgSystemLanguageFilter\__construct(), FinderIndexerQuery\processDates(), FinderIndexerQuery\processString(), FinderIndexerHelper\stem(), FinderIndexerHelper\tokenize(), FinderIndexer\tokenizeToDB(), et JHtmlString\truncate().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :UTF-8 aware alternative to ucfirst Make a string's first character uppercase or all words' first character uppercase
| string | $str | String to be processed |
| string | $delimiter | The words delimiter (null means do not split the string) |
| string | $newDelimiter | The new words delimiter (null means equal to $delimiter) |
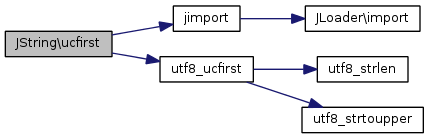
Références jimport(), null, et utf8_ucfirst().
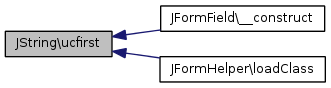
Référencé par JFormField\__construct(), et JFormHelper\loadClass().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
UTF-8 aware alternative to ucwords Uppercase the first character of each word in a string
| string | $str | String to be processed |
Références jimport(), et utf8_ucwords().
Référencé par JStringNormalise\toCamelCase().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
static |
Tests a string as to whether it's valid UTF-8 and supported by the Unicode standard.
Note: this function has been modified to simple return true or false.
| string | $str | UTF-8 encoded string. |
End of the multi-octet sequence. mUcs4 now contains the final Unicode codepoint to be output
((0xC0 & (*in) != 0x80) && (mState != 0)) Incomplete multi-octet sequence.
Références $i, elseif, et strlen().
Référencé par JFormRuleUrl\test().
Voici le graphe d'appel pour cette fonction : Voici le graphe des appelants de cette fonction :
|
staticprotected |